Makina Blog
PostgreSQL utilisations avancées de generate_series pour générer du contenu
Générer du contenu en masse permet de tester les requêtes, index et traitements complexes sur des volumes plus réalistes, d'avoir des approximations utiles des temps de réponses que l'on retrouvera en production. Dans cet article nous allons étudier des usages de generate_series() qui permettent de remplir tous types de tables.
english version available here.
Le postulat de départ est que nous avons deux tables à remplir (`contact` et `company`), avec des contraintes sur ces tables :
- une relation de clef étrangère qui rattache un `contact` à une `company`
- des contraintes sur les tailles de colonnes (comme les noms et prénoms)
- des contraintes spécifiques (CHECK) sur les dates (ainsi un `contact` dispose de dates de première et dernière interactions, et ces dates ont des contraintes entre elles, et ne peuvent pas être dans le futur, etc.)
L'autre postulat est que nous avons besoin de travailler avec plusieurs dizaines ou centaines de milliers d'enregistrements. Par exemple pour appliquer un processus métier qui devra être appliqué en production et mesurer la rapidité d’exécution de ce processus. Ou plus simplement pour tester la validité de notre plan d'indexation.
Il existe des outils qui peuvent générer du contenu, dans le monde Django on pourra par exemple utiliser des outils comme Factory Boy, ou d'autres. Mais nous allons montrer ici comment générer assez simplement ce même type de données, directement en SQL, de façon très très rapide (suffisamment par exemple pour être ajoutée dans un setUp de tests fonctionnels).
Il nous faut donc d'abord un modèle réaliste. Avec une table company`, une table `contact`, quelques index et deux trois lignes d'exemples. Vous pouvez récupérer `un script SQL d'exemple basic_schema.sql qui contient tout cela (direct download).
Et on peut même utiliser SQLFiddle pour visualiser cette structure en ligne. Mais je vous conseille de créer une base de test et de jouer ce SQL dedans, vous pourrez tester plus facilement les requêtes complexes dans votre propre base.
Génération de données simple
Commençons à utiliser `generate_series` pour générer des données :
-- tous les chiffres entre 1 et 100 (step 1 par défaut)
SELECT generate_series(1,100);
-- toutes les dates entre le 05/10/2010 et maintenant,
-- avec un step de 78 jours, 15 heures et 10 minutes
SELECT * FROM generate_series('2010-10-05 00:00'::timestamp,
CURRENT_TIMESTAMP,
'8 days 15 hours 12min');
On voit que c'est assez puissant (SQLFiddle1 SQLFiddle2).
Mais notre but c'est de pousser cette utilisation beaucoup plus loin.
Génération de noms à partir de syllabes
Commençons par cette requête qui va nous générer des noms de sociétés que nous utiliserons pour remplir la table `company` :
SELECT(
SELECT concat_ws(' ',name_first, name_last) as generated
FROM (
SELECT string_agg(x,'')
FROM (
select start_arr[ 1 + ( (random() * 25)::int) % 16 ]
FROM
(
select '{CO,GE,FOR,SO,CO,GIM,SE,CO,GE,CA,FRA,GEC,GE,GA,FRO,GIP}'::text[] as start_arr
) syllarr,
-- need 3 syllabes, and force generator interpretation with the '*0' (else 3 same syllabes)
generate_series(1, 3 + (generator*0))
) AS comp3syl(x)
) AS comp_name_1st(name_first),
(
SELECT x[ 1 + ( (random() * 25)::int) % 14 ]
FROM (
select '{Ltd,& Co,SARL,SA,Gmbh,United,Brothers,& Sons,International,Ext,Worldwide,Global,2000,3000}'::text[]
) AS z2(x)
) AS comp_name_last(name_last)
)
FROM generate_series(1,10000) as generator
On peut voir sur SQL Fiddle que cette requête un peu étrange fonctionne et nous génère effectivement 10 000 noms de sociétés, composé d'un assemblage de 3 syllabes et d'un mot de fin (genre "SOCOGEC 2000"ou "COGEFOR Worldwide"). La requête n'utilise aucune table, il n'y a même pas de modèle associé dans le SQL Fiddle.
Au sein de cette requête on retrouve des appels à `RANDOM()` qui vont nous permettre de faire varier les choix, les `% 14` et `% 16` sont importants, ils utilisent la taille effective des arrays de syllabes pour nous permettre de choisir une valeur au hasard dans l'array. La partie la plus complexe de la requête est le `+ (generator*0)` qui reprends l'identifiant généré dans `generate_series` et le multiplie par 0 (donc on en fait rien). Sans cet appel la sous-requête serait optimisée et non corrélée, et une seule combinaison de syllabe serait générée, on obtiendrait bien 10000 lignes, avec 10000 identifiants, mais le même nom de société à chaque ligne.
Une fois que l'on a trouvé un `SELECT` qui nous plaît il ne reste qu'à insérer son résultat dans la table en utilisant une requête d'insertion sous la forme:
INSERT INTO matable(field1, field2)
SELECT ..... -- (ici le select qu'on vient de trouver) ....
ON CONFLICT DO NOTHING;
La partie `ON CONFLICT` n'est pas disponible avant PostgreSQL 9.5, elle permet d'ignorer les erreurs de clefs uniques. Sur un postgreSQL plus vieux il vous faudra générer un select sans doublons (utilisez distinct par exemple), ici avec ce `DO NOTHING` je n'aurais pas de problèmes de doublons, ils seront rejetés en silence.
Sur notre schéma de départ on ajoute dans SQL Fiddle la génération de quelques sociétés et on voit qu'effectivement plus d'un tiers des sociétés générées étaient en doublons et n'ont pas été insérées en base.
Encore plus complexe
On a des sociétés. Maintenant essayons de trouver une requête `SELECT` qui nous afficherait toutes les colonnes nécessaires à une insertion de contact.
Sur le même modèle que les noms de sociétés on pourra assez facilement générer des noms et prénoms. ICI par exemple je génère des noms SQLFiddle. Remarquez ce qui se passe si je retire le + (generator*0)`, `on génère le même nom à chaque ligne).
On peut générer des identifiants de société bidons (un random entre 1 et 6300 par exemple) et aller retrouver la société rattachée à cet identifiant pour utiliser le nom de société dans un email. Email que l'on complétera avec le nom et prénom (sans les accents).
On peut choisir aléatoirement l'un des statuts parmi l'`ENUM` de statut du contact.
Mais il va aussi nous falloir des dates. date de création, de mise à jour, et des dates d'interaction avec ces contacts.
Pour cela je vais commencer par me faire une pseudo table de dates. Je veux pouvoir, pour un contact, piocher une date dans cette table, et m'en servir comme date de création. J'aurais ensuite d'autres colonnes de dates dans cette table qui seront situées après cette date de création (quelques semaines après pour une première date, et encore plus loin pour une seconde date).
En piochant ainsi dans cette table je pourrais générer des profils de dates de création du contact, et d'actions effectuées sur le contact.
Je vais utiliser des requêtes `UNION` dans cette collection de date pour avoir différentes répartitions, je veux pas mal de dates sur la dernière année, quelques autres dates sur les 5 dernières années, et moins de dates sur les 10 dernières années. Et bien sur je veux avoir tout cela dans le désordre, et avec un incrément qui va permettre de matcher ces dates comme s'il s'agissait d'une table avec un identifiant.
Le code source de ce sous-ensemble de 1083 lignes proposant chacune 3 dates est ici et on peut le voir en action avec SQLFiddle
rownum | base_date | date_up_to_7_days | date_up_to_3_months
--------+-------------------------------+-------------------------------+-------------------------------
1 | 2016-12-12 11:49:32.811583+01 | 2016-12-15 22:20:32.811583+01 | 2017-06-27 18:34:32.811583+02
2 | 2017-02-24 06:21:32.811583+01 | 2017-03-01 07:36:32.811583+01 | 2017-06-27 18:34:32.811583+02
3 | 2012-06-28 08:40:32.811583+02 | 2012-07-02 15:06:32.811583+02 | 2014-02-22 07:16:32.811583+01
4 | 2007-12-05 17:55:32.811583+01 | 2007-12-10 17:35:32.811583+01 | 2008-07-19 06:27:32.811583+02
5 | 2014-01-09 18:48:32.811583+01 | 2014-01-10 22:10:32.811583+01 | 2014-10-25 19:48:32.811583+02
6 | 2007-08-23 01:56:32.811583+02 | 2007-08-28 17:25:32.811583+02 | 2007-12-20 02:12:32.811583+01
...)
Ce type de sous ensemble pourra être utilisé dans ma requête comme une table grâce à l'utilisation de `WITH`
WITH dates1083 AS (
... -- ici le gros select de dates ...
)
SELECT * FROM
tbl1
INNER JOIN dates1083 ON tbl1.foo_id = dates1083.id
Cela permet de ne pas créer une table temporaire, elle est liée à la requête que je vais faire uniquement.
Cette requête, justement, avec toutes les pseudos colonnes dynamiques, réutilisant toutes un `generate_series` de base, va être un peu costaud.
En version simplifiée, où les gros générateurs sont remplacés par des [ blocs commentaire ] cela donne :
WITH dates1083 as (
... -- [ Here the whole 1083 *3 columns pseudo table generation ]
)
INSERT INTO contact(
con_id,
con_active,
con_firstname,
con_lastname,
con_mail,
date_create,
con_date_first_interaction,
con_date_last_interaction,
date_alter,
con_status,
comp_id
)
SELECT
id,
con_active,
CASE WHEN show_first_name THEN name_first ELSE NULL END as con_first_name,
CASE WHEN show_last_name THEN name_last ELSE NULL END as con_last_name,
-- con_mail
concat_ws('@',co [ ... Here string manipulations, with column from company, name and first name ... ] ) as mail,
-- date_create
dates1083.base_date as date_create,
-- con_date_first_interaction
CASE WHEN (has_1st_interact=true) THEN dates1083.date_up_to_7_days ELSE NULL END as date_1st_interact,
-- con_date_last_interaction
CASE WHEN (has_2nd_interact=true AND has_1st_interact=true) THEN dates1083.date_up_to_3_months
WHEN (has_2nd_interact=false AND has_1st_interact=true) THEN dates1083.date_up_to_7_days
ELSE NULL END as date_2nd_interact,
-- date_alter
CASE WHEN (has_2nd_interact=true AND has_1st_interact=true) THEN dates1083.date_up_to_3_months
WHEN (has_1st_interact=true) THEN dates1083.date_up_to_7_days ELSE dates1083.base_date END as date_alter,
-- con_status
con_status,
-- company link
main_sub.comp_id
FROM (
-- name_first
SELECT(
[ .. Here first name generator ... ]
),
-- name_last
(
[ .. Here last name generator ... ]
),
-- con_status
(
[ .. Here status enum choice generator ... ]
),
-- comp_id (used for joining company table, adding comp_name on email
(
select (random() * 10000)::int + (generator*0) as comp_id
),
-- base_date_num (used for joining dates1083 pseudo-table, and computing others dates from that
(
select (random() * 1083)::int + (generator*0) as base_date_num
),
-- con_active, something like 10% of false (inactive)
(
select ((random() * 10 + (generator*0)) > 1)::boolean as con_active
),
-- has_1st interaction something like 95%
(
select ((random() * 100 + (generator*0)) > 5)::boolean as has_1st_interact
),
-- has_2nd interaction something like 65%
(
select ((random() * 100 + (generator*0)) > 35)::boolean as has_2nd_interact
),
-- let's hide some non required fields sometimes
-- hiding 5 % of last_names
(
select ((random() * 100 + (generator*0)) > 5)::boolean as show_last_name
),
-- hiding 5 % of first_names
(
select ((random() * 100 + (generator*0)) > 5)::boolean as show_first_name
),
-- id
generator as id
FROM generate_series(1,100) as generator
) main_sub
INNER JOIN company ON company.comp_id = main_sub.comp_id
INNER JOIN dates1083 ON dates1083.rownum = main_sub.base_date_num
-- ignore conflicts of ids, but not any checks constraint failure (on dates for example)
ON CONFLICT DO NOTHING;
La voici complète et commentée, sans la partie INSERT. Il y a pas mal d'éléments dedans, je vous conseille de la copier dans une session pgadmin et de jouer avec les différentes colonnes. Il y a des générations de booléens dans des sous-requêtes, qui vont me permettre d'ajuster mes choix avec des CASE` dans les requêtes englobantes, afin de générer plus de variété, de mettre des `NULL` parfois dans les colonnes non requises, etc. On peut bien sûr la `voir dans SQL Fiddle avec ici le modèle déjà présent, car nous avons besoin de la table `company` pour générer la bonne colonne email.
id | con_active | con_first_name | con_last_name | mail | date_create | date_1st_interact | date_2nd_interact | date_alter | con_status | comp_id
----+------------+----------------+--------------------+----------------------------------------------------+-------------------------------+-------------------------------+-------------------------------+-------------------------------+------------+---------
1 | t | Coaïco | Takalaerjac | coaico.takalaerjac@cocaco-global.com | 2017-06-16 10:41:28.631596+02 | 2017-06-21 04:01:28.631596+02 | 2017-06-27 18:39:28.631596+02 | 2017-06-27 18:39:28.631596+02 | commercial | 4091
2 | t | Nnn | Otoerkingchen | nnn.otoerkingchen@sefrafor-international.com | 2016-03-12 04:25:28.631596+01 | 2016-03-15 07:34:28.631596+01 | 2016-10-22 05:57:28.631596+02 | 2016-10-22 05:57:28.631596+02 | external | 6055
3 | t | Cosyso | Steinroytakavur | cosyso.steinroytakavur@gecgipfor-global.com | 2016-12-16 10:35:28.631596+01 | 2016-12-18 18:11:28.631596+01 | 2016-12-18 18:11:28.631596+01 | 2016-12-18 18:11:28.631596+01 | production | 651
4 | t | Michavir | Ersteinotovur | michavir.ersteinotovur@gefroca-international.com | 2012-10-29 12:27:28.631596+01 | 2012-11-03 10:41:28.631596+01 | 2013-06-19 11:21:28.631596+02 | 2013-06-19 11:21:28.631596+02 | external | 2731
6 | t | Ennathche | Latakamcata | ennathche.latakamcata@gecforgim-united.com | 2016-12-15 12:29:28.631596+01 | 2016-12-19 11:12:28.631596+01 | 2017-06-27 18:39:28.631596+02 | 2017-06-27 18:39:28.631596+02 | external | 8740
8 | f | | Durjactakao' | borob.durjactakao-@forfrafor-gmbh.com | 2014-01-13 16:36:28.631596+01 | 2014-01-17 19:08:28.631596+01 | 2014-01-17 19:08:28.631596+01 | 2014-01-17 19:08:28.631596+01 | external | 1902
9 | t | Jamibo | Jacsteinlason | jamibo.jacsteinlason@gimgipgim-international.com | 2011-11-30 08:29:28.631596+01 | | | 2011-11-30 08:29:28.631596+01 | support | 3024
10 | t | Nathhnnath | Vurfürsteinking | nathhnnath.vurfursteinking@sosegip-sons.com | 2014-08-29 00:10:28.631596+02 | 2014-09-04 05:25:28.631596+02 | 2014-09-04 05:25:28.631596+02 | 2014-09-04 05:25:28.631596+02 | support | 6006
13 | t | Chepeche | Kleindurotoking | chepeche.kleindurotoking@sogegec-global.com | 2011-07-25 03:06:28.631596+02 | 2011-07-28 14:17:28.631596+02 | 2013-08-08 10:32:28.631596+02 | 2013-08-08 10:32:28.631596+02 | direction | 477
...)
Reste à insérer ces lignes dans la table contact. Comme on pouvait le voir sur la pseudo requête ci-dessus. Après la section WITH` nous avons une requête `SELECT`, la partie `INSERT INTO contact` est à coller juste avant ce SELECT. Ce qui donne `cette requête d'insertion, où l'on ajoute aussi le `ON CONFLICT DO NOTHING;`.
Je peux dès lors insérer 1000, 10 000 ou 100 000 contacts en changeant juste le chiffre du generate_serie final.
Pour SQL Fiddle la définition du modèle et ces requêtes atteignent quasiment la limite de taille (8000) et j'ai du retirer quelques définitions d'index et de la mise en forme, mais ça marche.
On peut aussi lister quelques contacts.
Où commencer à travailler sur des requêtes métiers complexes. Puisque justement le but est normalement de trouver les bon index métiers.
Pourquoi au fait?
Générer des données basées sur une physionomie de données réaliste, et sur des ensembles volumineux va permettre de valider une schéma d'indexation et d'optimiser les EXPLAIN.
La requête métier présentée dans ce précédent Fiddle et visible aussi directement ici) est plutôt horrible à optimiser, avec utilisation de `WINDOW`, de sous select, etc.
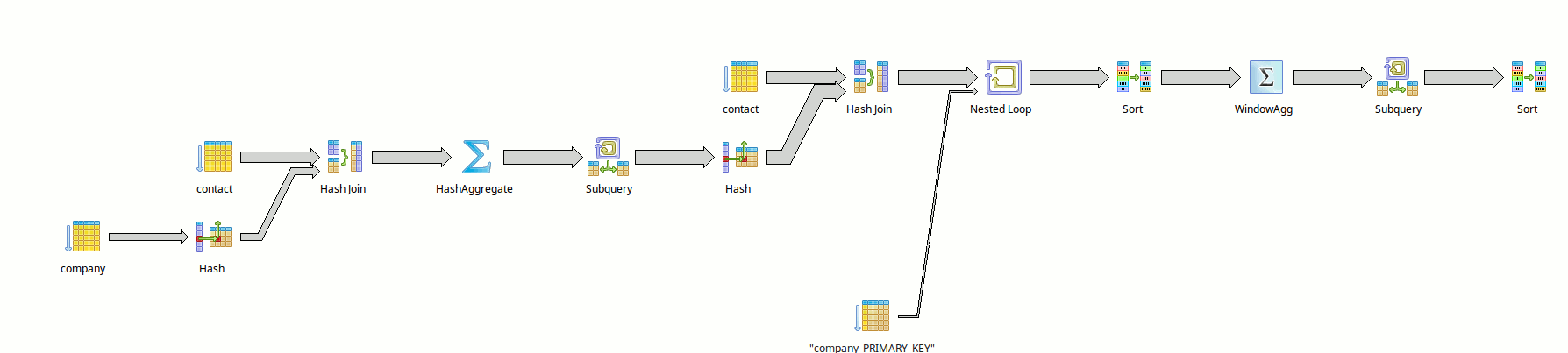
On peut par contre en fonction de la présence ou de l'absence de certains index (comme les indexs partiels sur les dates) obtenir différents schémas de explain, et chercher à trouver un compromis acceptable en terme d'indexation (entre nombre et taille des index, et durée d’exécution de la requête.
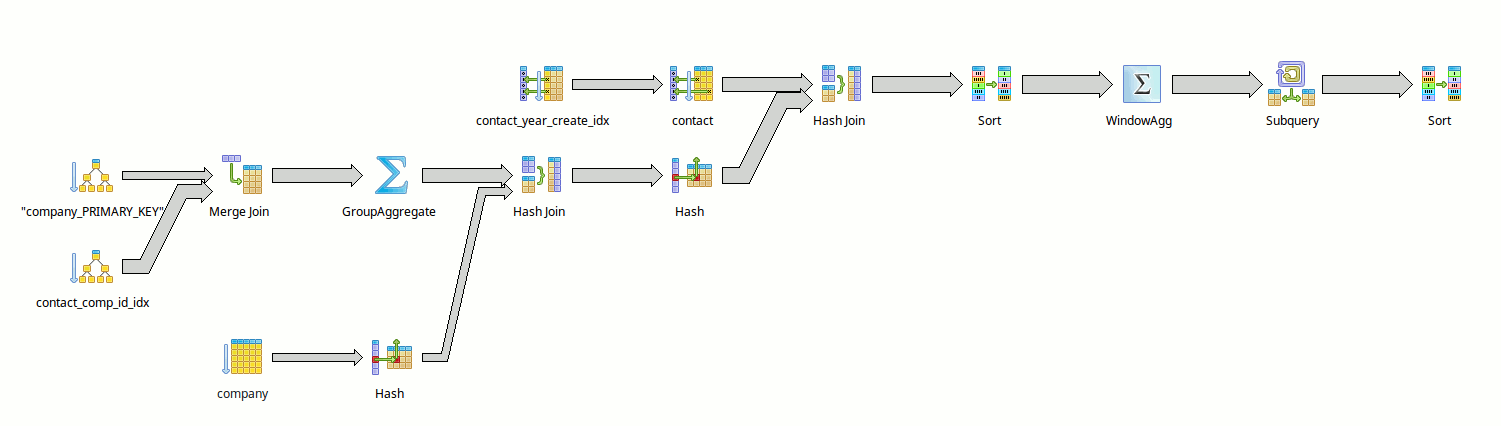
Mais cela est une autre histoire.
## Bonus
On peut bien sûr faire des variations sur les exemples proposés. Voici un lien pour un générateur de noms français prout-prout.
Et si vous voulez allez plus loin avec PostgreSQL n'hésitez pas à vous renseigner sur nos formations PostgreSQL!
Formations associées
Formations Outils et bases de données
Formation PostgreSQL
Nantes Du 8 au 10 septembre 2026
Voir la Formation PostgreSQLActualités en lien
Bibliothèque d’authentification OpenID Connect Django
Django
08/04/2025
DbToolsBundle, sortie de la version 2
Symfony
18/03/2025
Comment compresser son code applicatif de manière efficace avec Nginx et Brotli ?
DevOps
25/04/2023
